High-level Summarization
Research questions & main points
Linking unseen entities without in-domain labeled data.
Contribution
- Show strong reading comprehension models pre-trained on large unlabeled data can be used to generalize to unseen entities
- Propose a adaptive pre-training strategy (DAP)
Drawbacks
Notes
Resources/Assumptions explain:
- Single entity set. This assumes that there is a single comprehensive set of entities shared between training and test samples
- Alias table. Contains entity candidate for a given mention string and limits the possibilities to a relatively small set
- Frequency statistics. Use frequency statistics obtained from a large labeled corpus to estimate entity popularity and the probability of a mention string linking to an entity
- Structured data. Such as relationship tuples (A, B, C)
They made a weak assumption: the existence of an entity dictionary \(\varepsilon = \{(e_i,d_i)\}\) where \(d_i\) is a text description of entity \(e_i\). This paper defined domains as worlds: \(W=(M_W, u_W,\varepsilon_W)\), where \(M_W\) and \(u_W\) are distributions over mentions and documents from the worlds. \(\varepsilon_W\) is an entity dictionary associated with \(W\), and is disjoint.
Entity Linking
Candidate generation
This paper used BM25, which is a kind of variant of TF-IDF to measure similarity between mention string and candidate documents.
Candidate ranking
Denote mention \(m\) and candidate description \(e\), each represented by 128 word-piece tokens, concate as sequence pair \(([CLS]m[SEP]e[SEP])\) for the input of BERT. Mention words are signaled by a special embedding vector that is added to the mention word embeddings. (Position?)
The Transformer encoder produces a vector representation \(h_{m,e}\) of input pair, which is the output of the last hidden layer at the special pooling (special pooling?) token \([CLS]\). Entities in the given candidate set (generated from candidate generation step) are scored as \(w^Th_{m,e}\), where \(w\) is a learned parameter vector, and the model is trained using a softmax loss.
They implement two variants:
- Pool-Transformer Uses two deep Transformers to separately derive single-vector representations of \(h_m\) and \(h_e\); they take as input the mention in context and entity description respec- tively, together with special tokens indicating the boundaries of the texts: \(([CLS] m [SEP])\) and \(([CLS] e [SEP])\). This is a kind of 'Single vector representations for the two components'
- Cand-Pool-Transformer This architec- ture also uses two Transformer encoders, but intro- duces an additional attention module which allows he to attend to individual token representations of the mention in context.
Adaptation
This paper focus on using unsupervised pre-training to ensure that downstream models are robust to target domain data. There are two normal strategies for pre-training:
Task-adaptive pre-training Pre-trained on the source and target domain unlabeled data jointly with the goal of discovering features that generalize across domains. After pre-training, the model is fine-tuned on the source-domain labeled data
Open-corpus pre-training Instead of explicitly adapting to a target domain, this approach sim- ply applies unsupervised pre-training to large cor- pora before fine-tuning on the source-domain la- beled data (Such as BERT)
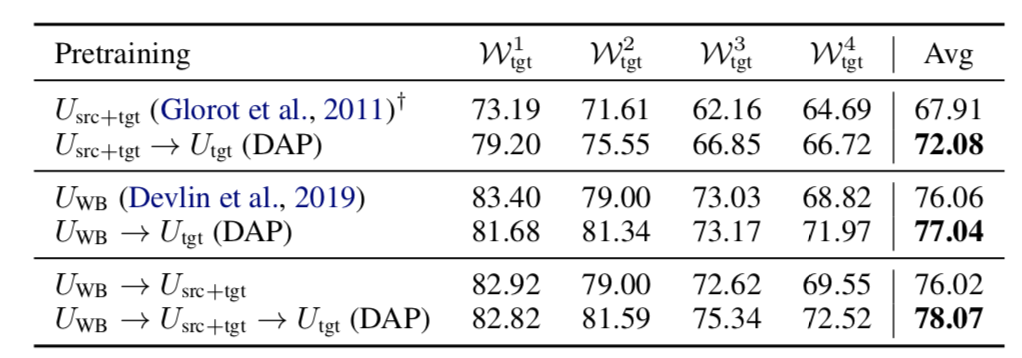
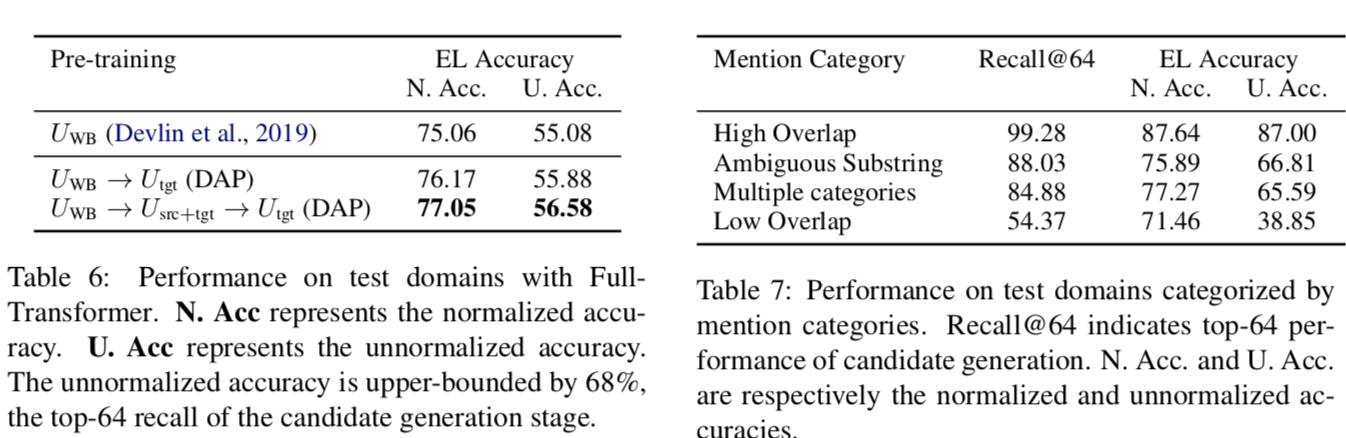
Domain-adaptive pre-training They propose to insert a penultimate domain adaptive pre-training (DAP) stage, where the model is pre-trained only on the target-domain data. DAP is followed by a final fine-tuning stage on the source-domain labeled data.
\(U_{src}\) denotes text segments from the union
of source world document distributions
\(U_{W_{src}^1} ...U_{W_{src}^n}\)
\(U_{tgt}\) denotes text segments from the document distribution of a target world \(W_{tgt}\)
\(U_{src+tgt}\) denotes randomly interleaved text segments from both \(U_{src}\) and \(U_{tgt}\)
\(U_{WB}\) denotes text segments from open corpora, which in our experiments are Wikipedia and the BookCorpus datasets used in BERT
They chain together a series of pre-training stages. For example, \(U_{WB}\) → \(U_{src+tgt}\) → \(U_{tgt}\) indicates that the model is first pre-trained on the open corpus, then pre-trained on the combined source and target domains, then pre-trained on only the target domain, and finally fine-tuned on the source-domain labeled data